What is Kubernetes? How industries are using Kubernetes?
To tell the story of how Kubernetes evolved from an internal container orchestration solution at Google to the tool that we know today, we dug into the history of it, collected the significant milestones & visualized them on an interactive timeline.
║ AGENDA ║
— — — — — — — — — — — — — — — — —
➤ History of Kubernetes
➤ Need of Kubernetes
➤ Kubernetes — A Container Management Tool
➤ What can Kubernetes do for you?
➤ Features of Kubernetes
➤ Few Myths About Kubernetes
➤ Kubernetes Architecture
➤ Components of a Kubernetes Cluster
➤ Challenges Solved By Kubernetes
History of Kubernetes


2003–2004: Birth of the Borg System
- Google introduced the Borg System around 2003–2004. It started off as a small-scale project, with about 3–4 people initially in collaboration with a new version of Google’s new search engine. Borg was a large-scale internal cluster management system, which ran hundreds of thousands of jobs, from many thousands of different applications, across many clusters, each with up to tens of thousands of machines.
2013: From Borg to Omega
- Following Borg, Google introduced the Omega cluster management system, a flexible, scalable scheduler for large compute clusters.
2014: Google Introduces Kubernetes
- Mid-2014: Google introduced Kubernetes as an open-source version of Borg.
- June 7: Initial release
- July 10: Microsoft, RedHat, IBM, Docker joins the Kubernetes community.
2015: The year of Kube v1.0 & CNCF
- July 21: Kubernetes v1.0 gets released. Along with the release, Google partnered with the Linux Foundation to form the Cloud Native Computing Foundation(CNCF). The CNFC aims to build sustainable ecosystems and to foster a community around a constellation of high-quality projects that orchestrate containers as part of a microservices architecture.
- November 3: The Kubernetes ecosystem continues to grow! Companies who joined: Deis, OpenShift, Huawei, and Gondor.
- November 9: Kubernetes1.1 brings major performance upgrades, improved tooling, and new features that make applications even easier to build and deploy.
- November 9–11: KubeCon 2015 is the first inaugural community Kubernetes conference in San Fransisco. Its goal was to deliver expert technical talks designed to spark creativity and promote Kubernetes education.
The year 2018:
- March 2: First Beta Version of Kubernetes1.10 announced. Users could test the production-ready versions of Kubelet TLS Bootstrapping, API aggregation, and more detailed storage metrics.
- May 1: Google launches the Kubernetes Podcast, hosted by Craig Box.
- May 2: DigitalOcean dives into Kubernetes, announces a new hosted Kubernetes product. DigitalOcean Kubernetes will provide the container management and orchestration platform as a free service on top of its existing cloud compute and storage options.
- May 4: Kubeflow 0.1 announced, which provides a minimal set of packages to begin developing, training, and deploying ML.
- May 21: Google Kubernetes Engine 1.10 is generally available and ready for the enterprise, featuring Shared Virtual Private Cloud, Regional Persistent Disks & Regional Clusters, Node Auto-Repair GA, and Custom Horizontal Pod Autoscaler for greater automation.
- June 5: Amazon EKS Becomes Generally Available. Amazon EKS simplifies the process of building, securing, operating, and maintaining Kubernetes clusters, and brings the benefits of container-based computing to organizations that want to focus on building applications instead of setting up a Kubernetes cluster from scratch.
- June 13: The Azure Kubernetes Service(AKS) is generally available. With AKS users can deploy and manage their production Kubernetes apps with the confidence that Azure’s engineers are providing constant monitoring, operations, and support for our customers’ fully managed Kubernetes clusters.
Need of Kubernetes
To understand the need of Kubernetes you have to understand the container first.
What are Containers?
Containers are a form of operating system virtualization. A single container might be used to run anything from a small microservice or software process to a larger application. A container has all the necessary executables, binary code, libraries, and configuration files. Compared to server or machine virtualization approaches, however, containers do not contain operating system images. This makes them more lightweight and portable, with significantly less overhead.
Benefits of containers
Containers are a streamlined way to build, test, deploy, and redeploy applications on multiple environments from a developer’s local laptop to an on-premises data center and even the cloud. Benefits of containers include:
- Less overhead: Containers require fewer system resources than traditional or hardware virtual machine environments because they don’t include operating system images.
- Increased portability: Applications running in containers can be deployed easily to multiple different operating systems and hardware platforms.
- Greater efficiency: Containers allow applications to be more rapidly deployed, patched, or scaled.
Problem with Containers


Containerization technology is really very fast, reliable, efficient, light-weight & scalable. But there are some problems with the management of its scalability. For servers, it is a very tedious task to handle in case if containers are not manageable when they scaled up. The problem is not scaling the containers, problem arise after that how it would be managed, how they can communicate with each other.
Problems with scaling up the containers:
➜ Containers could not communicate with each other.
➜ Containers had to be deployed appropriately.
➜ Containers had to be managed carefully.
➜ Autoscaling was not possible.
➜ Distributing traffic was still challenging.
So we can say regular containers can’t be enough, to bring more flexibility in scaling in detail we need something else to manage the containers & that is Kubernetes.
Kubernetes — A Container Management Tool

Kubernetes (also known as k8s or “Kube”) is an open-source container orchestration platform that automates many of the manual processes involved in deploying, managing, and scaling containerized applications.
It groups containers that make up an application into logical units for easy management and discovery. Kubernetes builds upon 15 years of experience running production workloads at Google, combined with best-of-breed ideas and practices from the community.
What can Kubernetes do for you?
With modern web services, users expect applications to be available 24/7, and developers expect to deploy new versions of those applications several times a day. Containerization helps package software to serve these goals, enabling applications to be released and updated in an easy and fast way without downtime. Kubernetes helps you make sure those containerized applications run where and when you want and helps them find the resources and tools they need to work. Kubernetes is a production-ready, open-source platform designed with Google’s accumulated experience in container orchestration.
Feature of Kubernetes

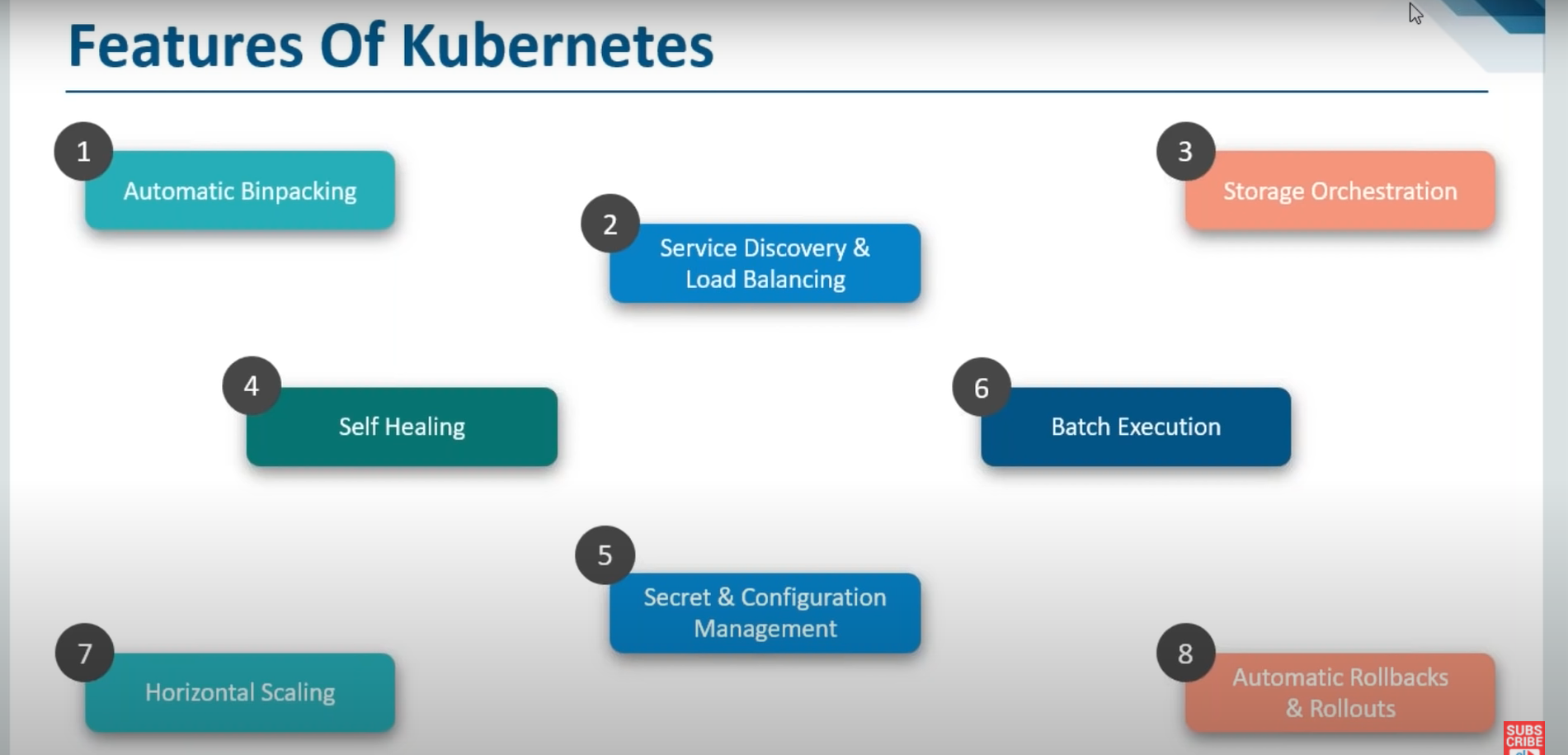
✦Automatic Bin packing
Automatic Binpacking is basically that Kubernetes packages your application and it automatically places containers based on their requirements & resources that are available.
✦Service Discovery & Load Balancing
Kubernetes assigns containers their own IP addresses & probably a single DNS name for a set of containers that are performing a logical operation. Also, there will be load balancing across them so you don’t have to worry about the load distribution.
✦Storage Orchestration
Kubernetes automatically mount the storage system of your choice. It can be either local storage or maybe on a public cloud providers such as GCP or AWS or even a network storage system such as NFS or other things.
✦Self Healing
Whenever Kubernetes realize that one of your containers has failed then it will restart that container on its own. In case if your node itself fails then Kubernetes would do in that case is whatever containers were running in that failed node those containers would be started in another node and of course you would have some more nodes in that cluster.
✦Batch Execution
Along with services Kubernetes can also manage your batch & CI workloads which is more of a DevOps role, right.
✦Secret & Configuration Management
That is the concept of where you can deploy & update your secrets and application configuration without having to rebuild your entire image & without having to expose your secrets in your stack configuration. It is not available with all the other tools & Kubernetes is the one who does that. You don’t have to restart everything & rebuild your entire container.
✦Horizontal Scaling
Scale your application up and down with a simple command, with a UI, or automatically based on CPU usage.
✦Automated Rollouts & Rollbacks
Kubernetes progressively rolls out changes to your application or its configuration, while monitoring application health to ensure it doesn’t kill all your instances at the same time. If something goes wrong, Kubernetes will rollback the change for you.
Few Myths About Kubernetes
Some people have misunderstood that Kubernetes is like docker which is a containerization platform that’s what people think. But it is not true Kubernetes is a container management platform that regularly monitors & manages the container. When you have multiple containers than to manage the appropriate role of Kubernetes comes into play. Kubernetes is not for Simple Architecture.
Kubernetes can’t be compared with the docker because it’s not the right set of parameters for comparing them.


What Kubernetes actually is…!!

But we can compare Kubernetes with Docker Swarm…!!
Docker Swarm
Docker swarm is a container orchestration tool, meaning that it allows the user to manage multiple containers deployed across multiple host machines. One of the key benefits associated with the operation of a docker swarm is the high level of availability offered for applications.
Kubernetes vs Docker Swarm


Kubernetes Architecture


Kubernetes Design Principles
The design of a Kubernetes cluster is based on 3 principles.
A Kubernetes cluster should be:
- Secure. It should follow the latest security best-practices.
- Easy to use. It should be operable using a few simple commands.
- Extendable. It shouldn’t favor one provider and should be customizable from a configuration file.
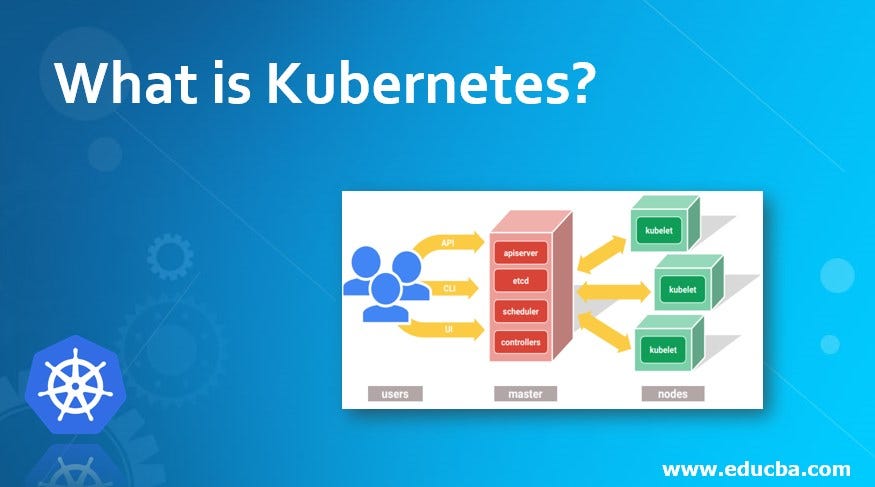
Components of a Kubernetes Cluster
A working Kubernetes deployment is called a cluster. You can visualize a Kubernetes cluster as two parts: the control plane and the compute machines, or nodes. Each node is its own Linux environment and could be either a physical or virtual machine. Each node runs pods, which are made up of containers.
This diagram shows how the parts of a Kubernetes cluster relate to one another:

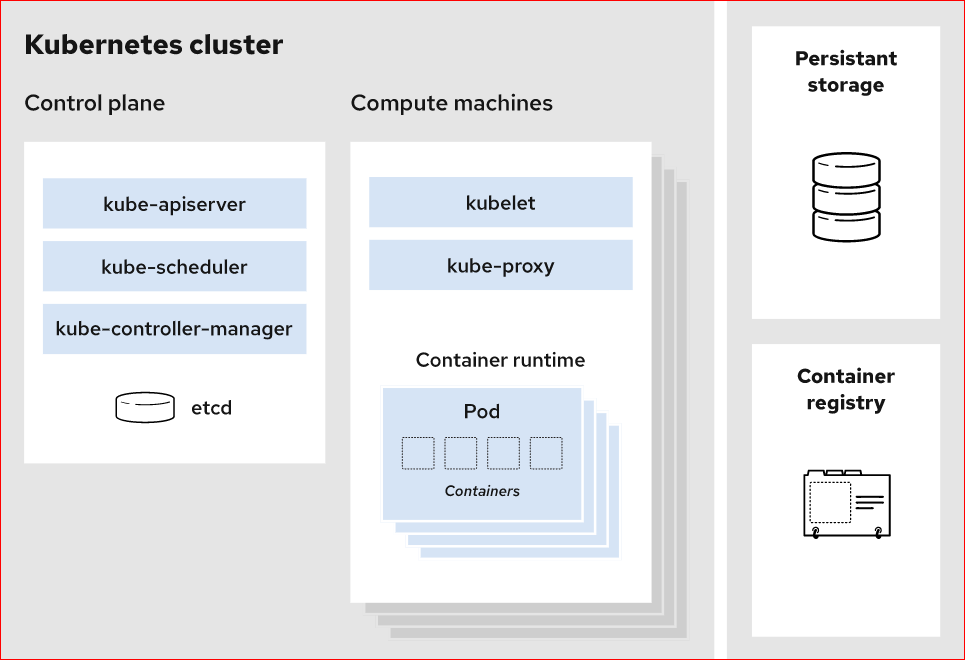
♕What happens in the Kubernetes Control plane?
❖Control plane
Let’s begin in the nerve center of our Kubernetes cluster: The control plane. Here we find the Kubernetes components that control the cluster, along with data about the cluster’s state and configuration. These core Kubernetes components handle the important work of making sure your containers are running in sufficient numbers and with the necessary resources.
The control plane is in constant contact with your compute machines. You’ve configured your cluster to run a certain way. The control plane makes sure it does.
☑ Kube-Apiserver
Need to interact with your Kubernetes cluster? Talk to the API. The Kubernetes API is the front end of the Kubernetes control plane, handling internal and external requests. The API server determines if a request is valid and, if it is, processes it. You can access the API through REST calls, through the kubectl command-line interface, or through other command-line tools such as kubeadm.
☑ Kube-scheduler
Is your cluster healthy? If new containers are needed, where will they fit? These are the concerns of the Kubernetes scheduler.
The scheduler considers the resource needs of a pod, such as CPU or memory, along with the health of the cluster. Then it schedules the pod to an appropriate compute node.
☑ kube-controller-manager
Controllers take care of actually running the cluster, and the Kubernetes controller-manager contains several controller functions in one. One controller consults the scheduler and makes sure the correct number of pods is running. If a pod goes down, another controller notices and responds. A controller connects services to pods, so requests go to the right endpoints. And there are controllers for creating accounts and API access tokens.
☑ etcd
Configuration data and information about the state of the cluster lives in etcd, a key-value store database. Fault-tolerant and distributed, etcd is designed to be the ultimate source of truth about your cluster.
♕What happens in Kubernetes Compute machines?
❖Compute machines
☑ Nodes
A Kubernetes cluster needs at least one compute node, but will normally have many. Pods are scheduled and orchestrated to run on nodes. Need to scale up the capacity of your cluster? Add more nodes.
☑ Pods
A pod is a smallest and simplest unit in the Kubernetes object model. It represents a single instance of an application. Each pod is made up of a container or a series of tightly coupled containers, along with options that govern how the containers are run. Pods can be connected to persistent storage in order to run stateful applications.
☑ Container runtime engine
To run the containers, each computes node has a container runtime engine. Docker is one example, but Kubernetes supports other Open Container Initiative-compliant runtimes as well, such as rkt and CRI-O.
☑ kubelet
Each compute node contains a kubelet, a tiny application that communicates with the control plane. The kublet makes sure containers are running in a pod. When the control plane needs something to happen in a node, the kubelet executes the action.
kube-proxy
Each compute node also contains kube-proxy, a network proxy for facilitating Kubernetes networking services. The kube-proxy handles network communications inside or outside of your cluster — relying either on your operating system’s packet filtering layer, or forwarding the traffic itself.
♕What else does a Kubernetes cluster need?
✜ Persistent Storage
Beyond just managing the containers that run an application, Kubernetes can also manage the application data attached to a cluster. Kubernetes allows users to request storage resources without having to know the details of the underlying storage infrastructure. Persistent volumes are specific to a cluster, rather than a pod, and thus can outlive the life of a pod.
✜ Container Registry
The container images that Kubernetes relies on are stored in a container registry. This can be a registry you configure or a third-party registry.
✜ Underlying infrastructure
Where you run Kubernetes is up to you. This can be bare metal servers, virtual machines, public cloud providers, private clouds, and hybrid cloud environments. One of the Kubernetes key advantages is it works on many different kinds of infrastructure.
Challenges Solved By Kubernetes
✿ CASE STUDY: Pearson
(World’s Largest Education Company With Kubernetes)


Challenge
A global education company serving 75 million learners, Pearson set a goal to more than double that number, to 200 million, by 2025. A key part of this growth is in digital learning experiences, and Pearson was having difficulty in scaling and adapting to its growing online audience. They needed an infrastructure platform that would be able to scale quickly and deliver products to market faster.
Solution
“To transform our infrastructure, we had to think beyond simply enabling automated provisioning,” says Chris Jackson, Director for Cloud Platforms & SRE at Pearson. “We realized we had to build a platform that would allow Pearson developers to build, manage and deploy applications in a completely different way.” The team chose Docker container technology and Kubernetes orchestration “because of its flexibility, ease of management and the way it would improve our engineers’ productivity.”
Impact
With the platform, there has been substantial improvements in productivity and speed of delivery. “In some cases, we’ve gone from nine months to provision physical assets in a data center to just a few minutes to provision and get a new idea in front of a customer,” says John Shirley, Lead Site Reliability Engineer for the Cloud Platform Team. Jackson estimates they’ve achieved 15–20% developer productivity savings.
✿ CASE STUDY: OpenAI
( AI research and deployment company)


Challenge
An artificial intelligence research lab, OpenAI needed infrastructure for deep learning that would allow experiments to be run either in the cloud or in its own data center, and to easily scale. Portability, speed, and cost were the main drivers.
Solution
OpenAI began running Kubernetes on top of AWS in 2016, and in early 2017 migrated to Azure. OpenAI runs key experiments in fields including robotics and gaming both in Azure and in its own data centers, depending on which cluster has free capacity. “We use Kubernetes mainly as a batch scheduling system and rely on our autoscaler to dynamically scale up and down our cluster,” says Christopher Berner, Head of Infrastructure. “This lets us significantly reduce costs for idle nodes, while still providing low latency and rapid iteration.”
Impact
The company has benefited from greater portability: “Because Kubernetes provides a consistent API, we can move our research experiments very easily between clusters,” says Berner. Being able to use its own data centers when appropriate is “lowering costs and providing us access to hardware that we wouldn’t necessarily have access to in the cloud,” he adds. “As long as the utilization is high, the costs are much lower there.” Launching experiments also takes far less time: “One of our researchers who is working on a new distributed training system has been able to get his experiment running in two or three days. In a week or two, he scaled it out to hundreds of GPUs. Previously, that would have easily been a couple of months of work.”
✿ CASE STUDY: HUAWEI
(Chinese multinational networking and telecommunications equipment and services company)


Challenge
A multinational company that’s the largest telecommunications equipment manufacturer in the world, Huawei has more than 180,000 employees. In order to support its fast business development around the globe, Huawei has eight data centers for its internal I.T. department, which have been running 800+ applications in 100K+ VM’s to serve these 180,000 users. With the rapid increase of new applications, the cost and efficiency of management and deployment of VM-based apps all became critical challenges for business agility. “It’s very much a distributed system so we found that managing all of the tasks in a more consistent way is always a challenge,” says Peixin Hou, the company’s Chief Software Architect and Community Director for Open Source. “We wanted to move into a more agile and decent practice.”
Solution
After deciding to use container technology, Huawei began moving the internal I.T. department’s applications to run on Kubernetes. So far, about 30 percent of these applications have been transferred to cloud-native.
Impact
“By the end of 2016, Huawei’s internal I.T. department managed more than 4,000 nodes with tens of thousands containers using a Kubernetes-based Platform as a Service (PaaS) solution,” says Hou. “The global deployment cycles decreased from a week to minutes, and the efficiency of application delivery has been improved 10 fold.”
Finally, we have done with our today’s agenda😊🙌.